Writing · AI Systems
How Granola Actually Works
And why it changed how I think about AI products.
By Arjun Bains
Published 21 Oct 2025
AI products often feel magical. You speak into a microphone and seconds later a perfect set of meeting notes appears. You assume some mysterious model did it but you never really know how. I was the same. I used tools like Granola, thought “wow, this is neat”, and moved on. But the more I built with AI myself, the more I wanted to understand what was actually happening.
So I took it apart. And what I found wasn’t magic at all. It was all engineering.. elegant, patient, and surprisingly attainable.

1. We use these systems every day without knowing how they work
Granola isn’t a single LLM call. It’s an orchestrated system built around precision, caching, and careful control of context. Here’s what I found when I traced the full flow end-to-end.
After you sign in, Granola uses a Google OAuth token to subscribe to your calendar through events.watch. That lets it watch meetings in real time. Your local cache receives those updates and quietly triggers a join notification as the slot begins.
Once you join, Granola starts streaming raw PCM audio (the clean, uncompressed signal) from both your mic and your system output into Deepgram’s speech-to-text API. Deepgram returns tiny JSON packets every few hundred milliseconds. Granola stitches those fragments together in memory, so you can open the live transcript instantly.
- Two audio sources are tracked: Me (your mic) and Them (system audio).
- After the call, the same audio is re-sent to Deepgram with
diarize=trueso speakers are clustered and labelled. - The audio itself is deleted. Granola keeps only transcript data: text, timing, speaker, and metadata.
2. What’s actually happening underneath
During the call, anything you type becomes a first-class signal. Those bullets are treated as higher-weight evidence than the raw transcript, which means you’re quietly steering the model by what you jot down.
When the meeting ends (or times out), Granola runs asummarize_meetingjob that consolidates everything it captured.
Now Granola has a structured record of what happened, enough to reason about. Each bullet you wrote is matched to the transcript snippet nearest in time (±30–45 s). Boundaries are extended to full sentences, then snippets are scored by proximity, semantic similarity, speaker importance, and novelty. The closest match becomes the evidence attached to that bullet.
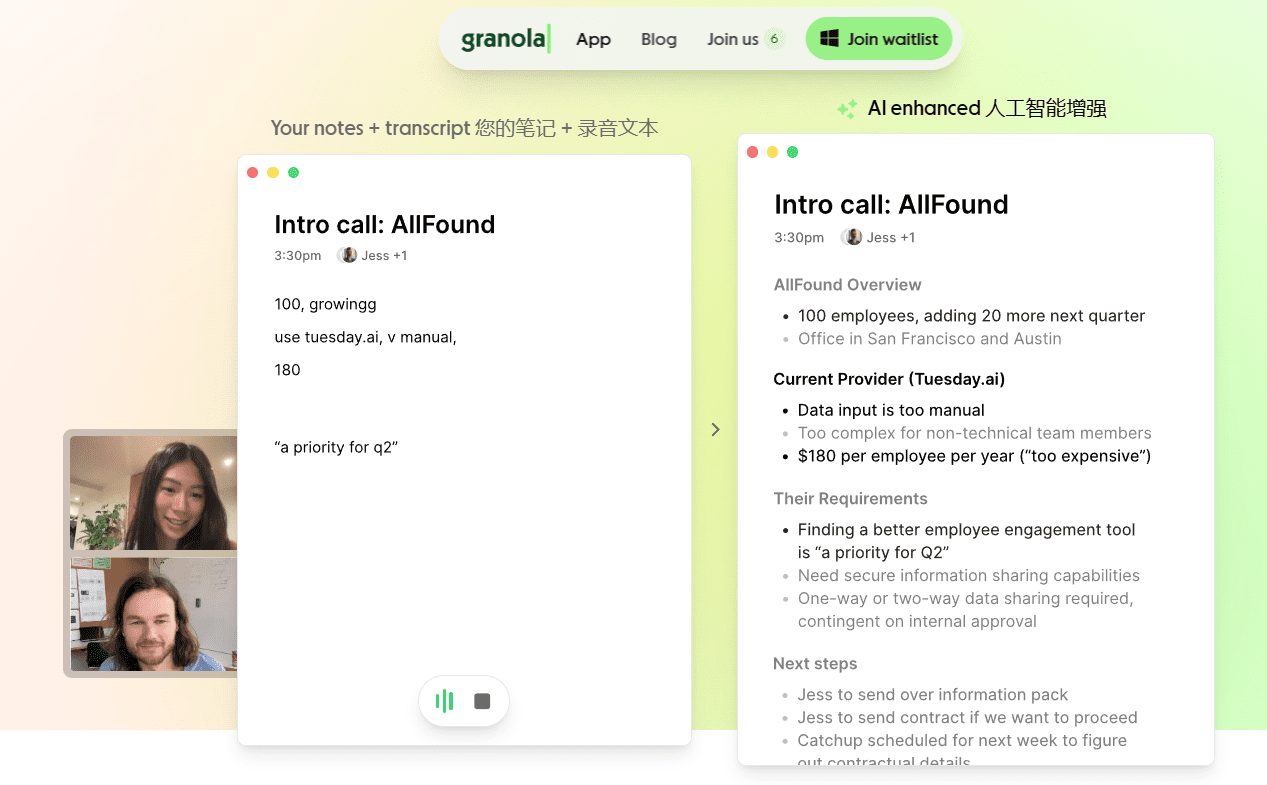
Finding what you missed
A second pass hunts for lines that sound important but don’t match any bullet. It looks for phrases like “we decided”, “I’ll”, “can you”, “on Monday”, or anything with numbers, money, or deadlines. Each gets a salience score and the strongest few are added back into the note.
To stay within the LLM’s context window (around 10k tokens), Granola removes near-duplicates, shortens long monologues, and trims low-priority snippets if the context is still too long. That balancing act, keeping factual density high while staying cheap and fast, is a quiet craft in itself.
All of this becomes a fact packet: the single JSON object the model receives.
{
"metadata": {"title": "ACME Pricing Discussion", "date": "2025-02-14"},
"user_bullets": [
{"id": "B1", "text": "Need pricing by Friday"},
{"id": "B2", "text": "Pilot limited to 3 features"}
],
"snippets": [
{"id": "S11", "speaker": "Alice", "text": "Can you send pricing by Friday?"},
{"id": "S12", "speaker": "Alice", "text": "For the pilot we only need dashboard, alerts, export."}
],
"entities": {
"dates": ["2025-02-14", "2025-02-17"],
"owners": ["Alice"],
"actions": ["send pricing", "limit pilot"]
}
}3. Writing, evaluating, and repairing the draft
Granola splits rules from data. The system message tells the model how to behave: use only given facts, mark added lines [AI], preserve bullets, avoid invented data. The user message contains the fact packet and a single instruction: “Produce the meeting note now.”
This separation is why outputs feel stable and auditable. It’s impossible for the model to treat instructions as content.
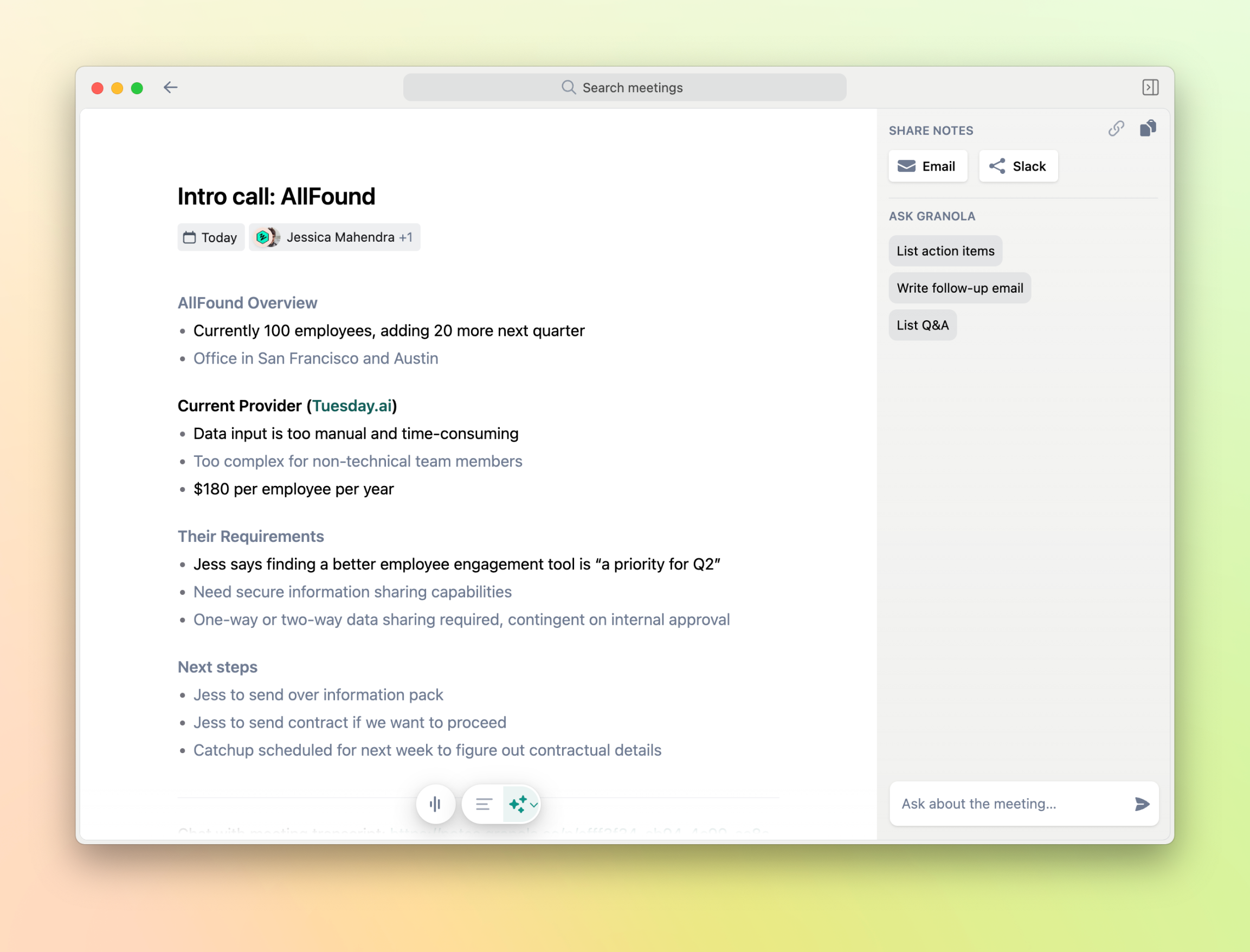
The LLM walks through every section, expands each bullet, formats tasks as checkboxes, and outputs a Markdown draft. Then a critic model checks it against the fact packet. It flags unsupported numbers, missing sections, or tasks without owners. If something fails, Granola builds a small repair prompt listing only what to fix, sends it back, and checks again. Usually one or two loops are enough.
Finally, deterministic code takes over: [AI] lines are styled grey, tasks become structured JSON, and a provenance map links each note section back to its source snippet. Every sentence ends up with a receipt.
“The hardest part isn’t training models. It’s shaping them.”
4. What I realised after looking at all this
Once you see how granular it is, you stop thinking “AI wrote that” and start thinking “this is a machine pipeline designed by obsessive humans.” There’s no single genius model behind it. It’s a set of disciplined systems cleaning, filtering, and checking to make the model’s job easy.
- Define what counts as a fact, and discard the rest.
- Shape prompts so the model can’t hallucinate.
- Design evals that know when to rerun the model.
After pulling Granola apart, I felt something new: these systems aren’t out of reach. They look complex, but they’re just layers of reasoning, cleaning, and feedback. If you know how to wire APIs, structure context, score evidence, and test outputs, you can build something similar. Not overnight, but with focus.
The hardest part isn’t training models. It’s shaping them. Granola works because the team made hundreds of small decisions: how to rank snippets, how to map bullets, how to compress text, how to score truth. That’s the real product work.